connected systems of people working together toward shared objectives, often through internal teams and external partners such as suppliers, universities, accelerators, customers, and startups.
operator basis: a set of matrices that can be used to express any matrix as a linear combination of the basis matrices
(acbd)=a∣0⟩⟨0∣+b∣0⟩⟨1∣+c∣1⟩⟨0∣+d∣1⟩⟨1∣
One of the basis elements is: ∣0⟩⟨0∣⊗∣0⟩⟨0∣=∣00⟩⟨00∣
Similarly ∣0⟩⟨0∣⊗∣0⟩⟨1∣=∣00⟩⟨01∣
In total, the tensor products yields 4×4=16 basis elements for the space of 4×4 matrices: {∣00⟩⟨00∣,∣00⟩⟨01∣,∣00⟩⟨10∣,∣00⟩⟨11∣,∣01⟩⟨00∣,∣01⟩⟨01∣,…,∣11⟩⟨11∣}.
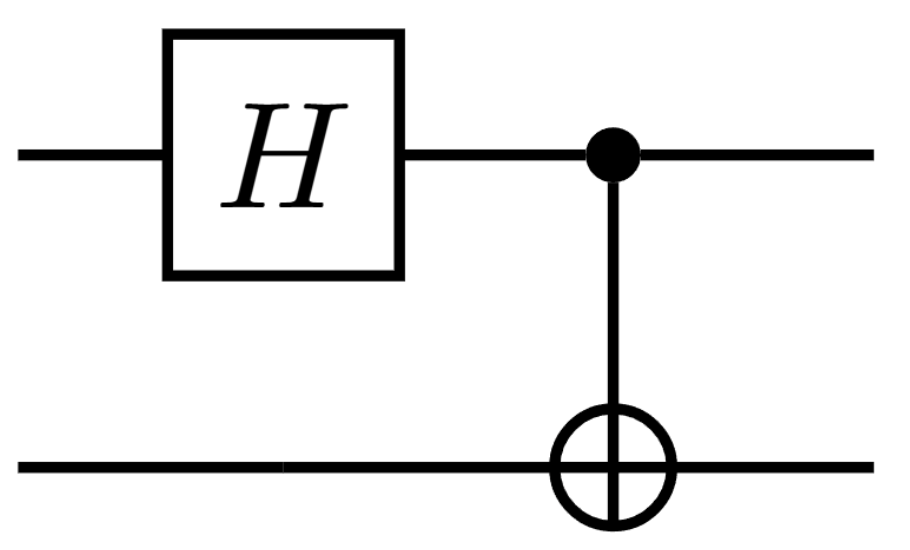
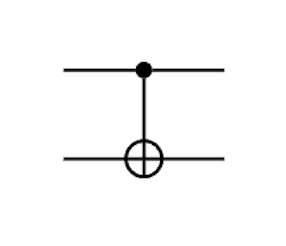
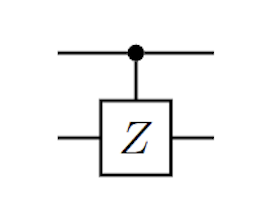
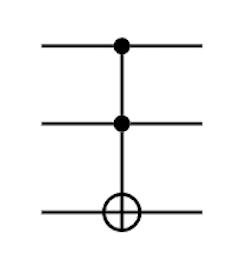
When gates act independently, it doesn't matter the order in which they are apply with the understanding that if only a single gate is applied, identity acts on the other qubits.
(U1⊗U2)=(I⊗U2)(U1⊗I)=(U1⊗I)(I⊗U2)
Example: Apply X to qubit 1 and H to qubit 2, starting with ∣00⟩:
a process by which new innovations and technological advancements ("creative")
desmantle long-standing economic structures, practices, and organizations ("destruction")
while creating new markets and opportunities
Disruptive Innovation
a process where a smaller company successfully challenges estabilished businesses bgy offering simpler, more affordable, or more accessible products or services.
low-cast, low-performance, alternative, improve over time and displace established playwers
Innovator's Dilemma
successful, well-managed companies often fail when disuptive technologies emerge
even when they do everything "right" according to traditional management principles.
Sustaining Innovation
Disruptive Innovation
Improves existing products
Creates new markets or value
Higher margins
Initially lower margins
High-end customers
Low-end market segments
Sustaining Innovation: Tesla improving battery range
Innovation can create benefits (growth, efficiency, solutions) but also risks (inequality, pollution, privacy loss).
Responsible Innovation is about developing new techonologies, products, or services in a way that is ethically acceptatble, socially desirable, and environmentally sustainable, while actively considering their potential impacts on society.
Anticipation: Exploring possible risks, unintended consequences, and long-term effects.
Reflexivity: Innovators reflecting on their own values, assumptions, and biases.
Inclusion: Engaging stakeholders (citizens, users, regulators, communities), not just engineers or investors shaping outcomes.
Responsiveness: Ability to change direction if concerns arise.
Product questions
Process questions
Purpose questions
How will the risks and benefits be distributed?
How should standards be drawn up and applied?
Why are researchers doing it?
What other impacts can we anticipate?
How should risks and benefits be defined and measured?
Are these motivations transparent and in the public interest?
Threat of New Entrants: Profitable industries that yield high returns will attract new firms. New entrants eventually will decrease profitability for other firms in the industry.
Threat of Substitutes: A substitute product uses a different technology to try to solve the same economic need.
Bargaining Power of Customers: The market outputs. The ability of customers to put the firm under pressure, which also affects the customer's sensitivity to price changes.
Bargaining Power of Suppliers: The market inputs. Suppliers of raw materials, components, labor, and services (such as expertise) to the firm can be a source of power over the firm when there are few substitutes.
Competitive rivalry: For most industries the intensity of competitive rivalry is the major determinant of the competitiveness of the industry.
Expected (Basic or Must-be) Attribute: whose presence doesn't directly increase satisfaction, but their absence causes extreme dissatisfaction.
car: a functioning brake is a must be quality
hotel: providing a clean room is a basic necessity
One-Dimensional (Performance) Attribute: can both satisfy and dissatisfy customers depending on their execution.
car: acceleration
hotel: waiting service at a hotel
Attractive (Delight) Attribute: differentiate products and services, creating a "wow factor" and delighting customers when present, but causing no dissatisfaction when absent.
car: advanced parking sensor
hotel: providing free food
Indifferent Attribute
car: the color of the car
hotel: highly polite speacking and very prompt responses not be necessary to satisfy customers
Reverse Attribute
web: auto-playing videos/audio
venue: unnecessary security checks at the entrance of a venue
As customer expectations change with the level or performance from competing products, attributes can move from delighter to performance need and then to basic need.
Ad-Supported: Provide content or services for free to one party while selling listneners, viewers, or "eyeballs" another party.
Auction: Allow a merket-and its users-to set the price for goods and services.
Bundled Pricing: Sell in a single transaction two or more items that could be sold as standalong offerings.
Cost Leadership: Keep variable costs low and sell high volumes at low prices.
Disaggregated Pricing: Allow customers to buy exactly-and only-what they want.
Financing: Capture revenue not from the direct sale of a product but from structured payment plans and after-sale interest.
Flexible Pricing: Vary prices for an offering based on demand.
Float: Receive payment prior to building the offering; earn interest on that money prior to delivering the goods.
Forced Scarcity: Limit the supply of offerings available, by quantity, time frame, or access, to drive up demand and/or prices.
Freemium: Offer basic services for free while charging a premium for advanced or special features.
Installed Base: Offer a "core" product for slime margins (or even a loss) to drive demand and loyalty; then realize profit on additional products and services.
Licensing: Grant permission to a group or individual to use your offering in a defined way for a specified payment.
Membership: Charge a time-based payment to allow access to locations, offerings, or services that non-members don't have.
Metered Use: Allow customeres to pay only for what they use.
Microtransactions: Sell many items for as little as a dollar-or even only one cent- to drive impulse purchases.
Premium: Price at a higher margin than competitors, usually for a superior product, offering, experience, service, or brand.
Risk Sharing: Waive standrad fees or costs if certain metrics aren't achieved, but receive outsize gains when they are.
Scaled Transactions: Maximize margins by pursuing high-volume, large-scale transactions when unit costs are relatively fixed.
Subscriptiuon: Create predictable cash flows by charging customers upfront (a one time or recurring fee) to have access to the product or service orver time.
Switchboard: Connect multiple sellers with multiple buyers. The more buyers and sellers who join, the more valuable the switchboard becomes.
User-Defined: Invite customers to set the prcie they wish to pay.
Alliances: Share risks and revenues to jointly improve individual competitive advantage.
Collaboration: Partner with others for mutual benefit.
Complementary partnering: Leverage assets by sharing them with companies that serve similar markets but offer different products and services.
Consolidation: Acquire multiple companies in the same market or complementary markets.
Coopetition: Join forces with someone who would normally be your competitior to achieve a common goal.
Franchising: License business principles, processes, and brand to paying partners.
Merger/Acquisition: Combine two or more entities to gain accesss to capabilities and assets.
Open Innovation: Obtain access to processes or patents from other companies to leverage, extend, and build on expertise, and/or do the same with internal IP and processes.
Secondary Markets: Connect waste streams, by-products, or other alternative offerings with those who want them.
Supply Chain Integration: Coordinate and integrate information and/or processes across a company or different parts of the value chain.
Asset Standardization: Reduce operating costs and increase connectivity and modularity by standardizing your assets.
Competency Center: Cluster resources, practices, and expertise into centers that support functions across the organization to increase efficiency and effectiveness.
Corporate University: Provide job-specific or company-specific training for managers.
Decentralized Management: Devolve decision-making governance closer to the people or business interfaces.
Incentive Systems: Offer rewards (financial or non-financial) to provide motivatino for a particular course of action.
IT Integration: Integrate technology resources and applications.
Knowledge Management: Share releavant information internally to reduce redundancy and improve job performance.
Organizational Design: Make from follow function and align infrastructure with core qualities and business processes.
Outsourcing: Assign to a vendor responsibility for developing or maintaining a ssystem.
Context-Specific: Offer timely access to offerings that are appropriate for a specific location, occasion, or situation.
Cross-Selling: Offer appealing additional products, services, or information that will enhance an experience in situations where customers are likely to want to buy them.
Diversification: Add and expand into new or different channels.
Experience Center: Create space that encourages your customers to interact with your offerings—but purchase them through a different (and often lower cost) channel.
Flagship Store: Create a retail outlet to showcase quintessential brand and product attributes.
Go Direct: Skip traditional retail channels and connect directly with customers.
Indirect Distribution: Use others as resellers who take responsibility for delivering an offering to the final user.
Multi-Level Marketing: Sell bulk or packaged goods to an affiliated but independent sales force that turns around and sells it for you.
Non-Traditional Channels: Employ novel and relevant avenues to reach and service customers.
On-Demand: Deliver goods in real-time whenever or wherever they are desired.
Pop-Up Presence: Create a noteworthy but temporary environment to showcase and/or sell offerings.
Autonomy and Authority: Grant users the power to shape their own experience.
Community and Belonging: Facilitate visceral connections to make people feel they are part of a group or movement.
Curation: Create a distinct point of view to build a strong identity for yourself and give your followers exactly what they want.
Experience Automation: Remove the burden of repetitive tasks from users to simplify their lives and make new experiences seem magical.
Experience Enabling: Extend the realm of what’s possible to offer a previously improbable experience.
Experience Simplification: Reduce complexity and focus on delivering specific experiences exceptionally well.
Mastery: Help customers to obtain great skill or deep knowledge of some activity or subject.
Personalization: Alter a standard offering to allow the projection of the customer’s identity.
Status and Recognition: Offer cues that confer meaning, allowing users—and those who interact with them—to develop and nurture aspects of their identity.
Whimsy and Personality: Humanize your offering with small flourishes of on-brand, on-message ways of seeming alive.
Keeley, L., Walters, H., Pikkel, R., & Quinn, B. (2013). Ten Types of Innovation: The Discipline of Building Breakthroughs. John Wiley & Sons, Incorporated.