RAG, 검색 증강 생성
· 4 min read

Owner
RAG 개요
RAG 개념
- LLM의 출력을 최적화하여 응답을 생성하기 전 학습 데이터 소스 외부의 지식 베이스 데이터를 참조하도록 하는 기술
RAG의 배경
| LLM의 문제점 | 설명 | RAG 기대효과 |
|---|---|---|
| 환각 | 답변이 없을 때 허위정보 제공 | 독점 데이터 활용 정보 제공 |
| 최신 데이터 | 일반적인 정보 제공 | 구체적 정보 제공 |
| 신뢰성 | 신뢰할 수 없는 출처로부터의 응답 제공 | 신뢰할 수 있는 정보 제공 |
RAG의 구성도 및 절차
구성도
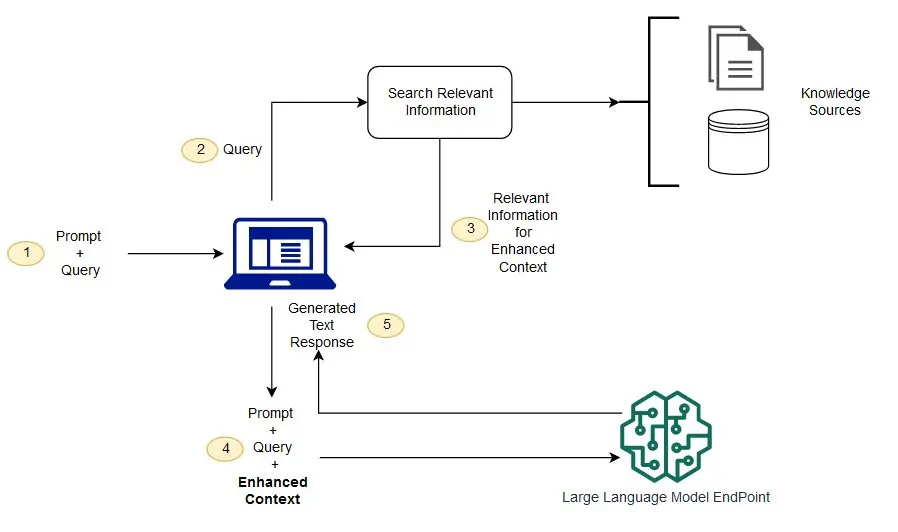
웹인터페이스 -> 벡터데이터베이스 -> LLM
구성요소
| 구분 | 설명 | 특징 |
|---|---|---|
| 웹인터페이스 | 질의 가능한 웹 인터페이스 | 챗봇 형태로 사용 |
| 벡터데이터베이스 | 임베딩 데이터 저장 | 최신/프라이빗 데이터 반환 |
| LLM | 자연어처리, 일반 지식 응답 | 임베딩 데이터 포함 응답 |
RAG 절차
- 외부 데이터 생성 및 준비: 텍스트, 이미지, 파일 등 다양한 소스로 임베딩 후 벡터DB 저장
- 관련 정보 검색: 질문을 기반으로 벡터 유사도 기반 데이터 검색
- LLM 프롬프트 확장: 검색된 데이터는 LLM 프롬프트와 결합하여 응답 반환
- 외부 데이터 업데이트: 벡터DB에 새로운 데이터를 주기적으로 업데이트하여 최신화
파인튜닝과 RAG 비교
| 구분 | 파인튜닝 | 검색증강생성 |
|---|---|---|
| 방식 | 특화데이터를 모델이 재학습 | 데이터 소스 추가 제공으로 모델 성능 향상 |
| 데이터 규모 | 작음 | 대규모 지식 베이스 |
| 모델 조정 | 재학습으로 모델이 새로운 데이터로 조정됨 | 추가 학습 없어 모델 조정 불필요 |
| 비용 | 고비용, 모델 전체 재학습 | 저비용 |
| 장점 | 적은 데이터로 학습 가능, 특정 작업에서 효과적 성능 향상 | 재학습 불필요, 과적합 위험 없음, 최신 데이터 반영 |
| 단점 | 고품질 데이터 확보 어려움 과적합, 편향, 환각 고비용 | LLM 모델에 따른 답변 품질 저하 소스 데이터 속성에 맞는 임베딩 모델 검토 필요 |