AutoGPT
· 약 1분

AutoGPT 개념
- GPT-4 기반으로 질문의 태스크를 생성하고, 에이전트는 그 과정을 반복하여 점진적으로 목표를 달성하는 기술
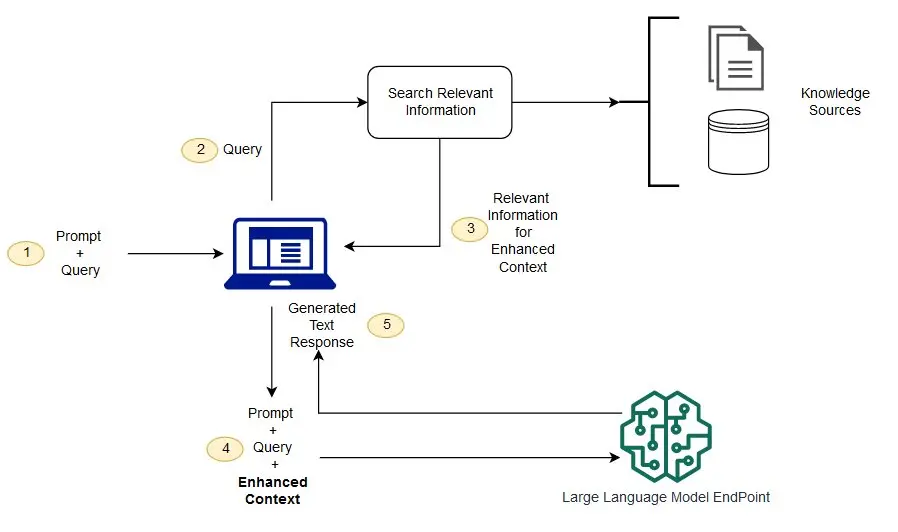
AutoGPT 구성도 및 구성요소
AutoGPT 구성도
AutoGPT 구성요소
| 구성요소 | 설명 | 예시 |
|---|---|---|
| 사용자 입력 | AutoGPT에 제공되는 목표 또는 작업 | 이메일 자동 답변 생성 |
| LLM | 태스크를 생성하기 위해 사용되는 언어 모델 | GPT-4 |
| 에이전트 | 사용자 입력을 기반으로 태스크를 수행, 피드백 루프를 통해 결과를 개선 | 이메일 자동 답변 생성 에이전트 |
| 피드백 루프 | 작업의 결과를 반복적으로 입력으로 사용하여 결과를 개선 | 결과 수정 및 재입력 |
AutoGPT 활용
| 적용 분야 | 활용 예시 | 설명 |
|---|---|---|
| 소프트웨어 개발 | 자동 코드 생성 | 어플리케이션 전체 자동 생성 |
| 디지털 마케팅 | 콘텐츠 추천 시스템 | 사용자의 활동을 기반한 개인화된 콘텐츠를 추천 |
| 정보 관리 | 자동 문서 요약 | 긴 문서를 요약하여 핵심 정보 제공 |
AutoGPT 성공포인트
- OpenAI API를 사용하여 비용 절감을 위해 단계별로 사람의 확인이 필요한 구조이나, Local sLLM으로 교체시 원하는 결과를 얻기까지의 비용 및 프로세스 절감 가능