K-means, DBSCAN 클러스터링
· 약 1분

클러스터링 개념
- 데이터 포인터들을 여러 군집으로 나누어 각 군집 간 유사성을 최소화, 군집 내 유사성을 최대화하는 비지도학습 알고리즘
- 데이터 내 잠재적 패턴, 그룹 발견, 군집별 맞춤 전략 수립, 군집별 전처리 및 축소
K-means, DBSCAN 클러스터링 개념, 비교
K-means 클러스터링 개념 및 특징
| 구분 | 내용 |
|---|---|
| 개념도 | 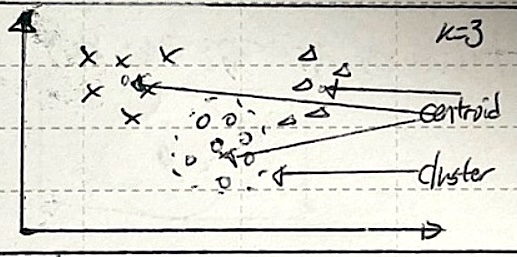 |
| 개념 | 데이터셋을 K개의 클러스터로 나눠 각 데이터가 가장 가까운 클러스터 중심에 할당하여 군집화하는 알고리즘 |
| 특징 | 초기 중심점 설정 민감, 이상치 민감 |
| 가벼운 시간 복잡도, 구형 클러스터 적합 |
DBSCAN 클러스터링 개념 및 특징
| 구분 | 내용 |
|---|---|
| 개념도 | 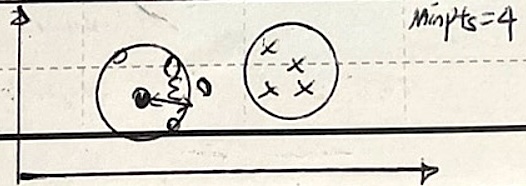 |
| 개념 | 밀도가 높은 지역에서 클러스터를 형성하고, 밀도가 낮은 지역은 노이즈로 간주하는 알고리즘 |
| 특징 | 클러스터 모양이 불규칙해도 좋은 성능 |
| 입실론 거리와 최소 포인트 수 조정이 성능의 핵심 요소 |
K-means, DBSCAN 클러스터링 비교
| 구분 | K-means | DBSCAN |
|---|---|---|
| 기반 | 거리기반 | 밀도기반 |
| 클러스터 형태 | 구형 클러스터 적합 | 임의 모양 식별 가능 |
| 노이즈 처리 | 약함 | 강함 |
| 처리 속도 | 빠름 | 느림 |
| 초기화 | 초기 중심점 선택 중요 | 덜 민감 |
클러스터링 고려사항
- 데이터 크기, 형태, 노이즈에 따라 적절한 알고리즘 선택 필요
- Dunn Index, Silhouette Coefficient 등의 지표로 클러스터링 결과 평가 후 하이퍼파라미터 조정