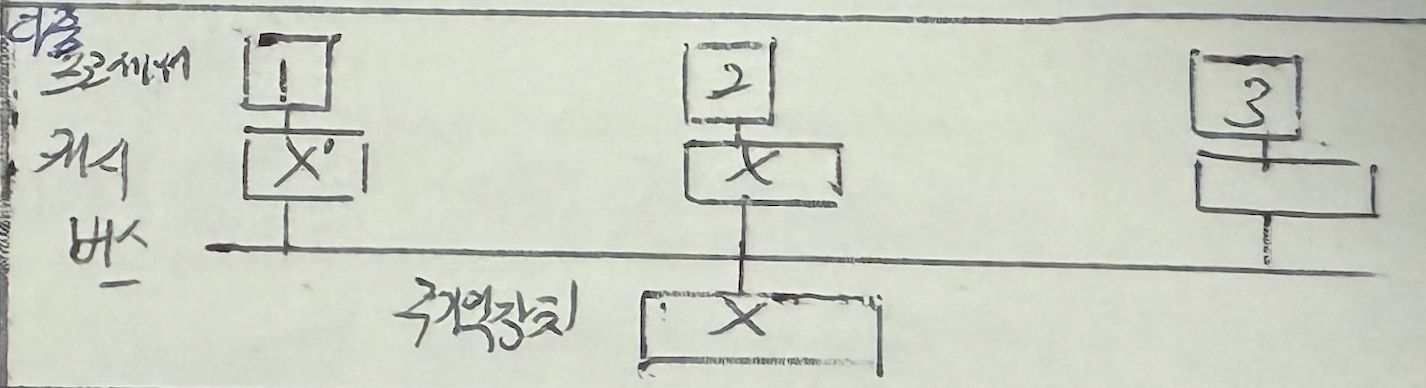
| SW 기법 | 공유 캐시 사용 | 모든 프로세서가 하나의 공유 캐시를 사용 |
| | 항상 캐시 일관성이 유지 |
| | 프로세서 간 캐시 액세스 충돌로 성능 저하 초래 |
| 공유 변수 캐시 미사용 | 공유변수를 캐시에 저장하지 않는 기법 |
| | 캐시 저장 불가능 데이터: Lock 변수, 프로세스 큐와 같은 공유 데이터 구조, 입출력 영역에 의해 보호되는 데이터 |
| | 캐시 적중률 저하 및 I/O 성능 저하 초래 |
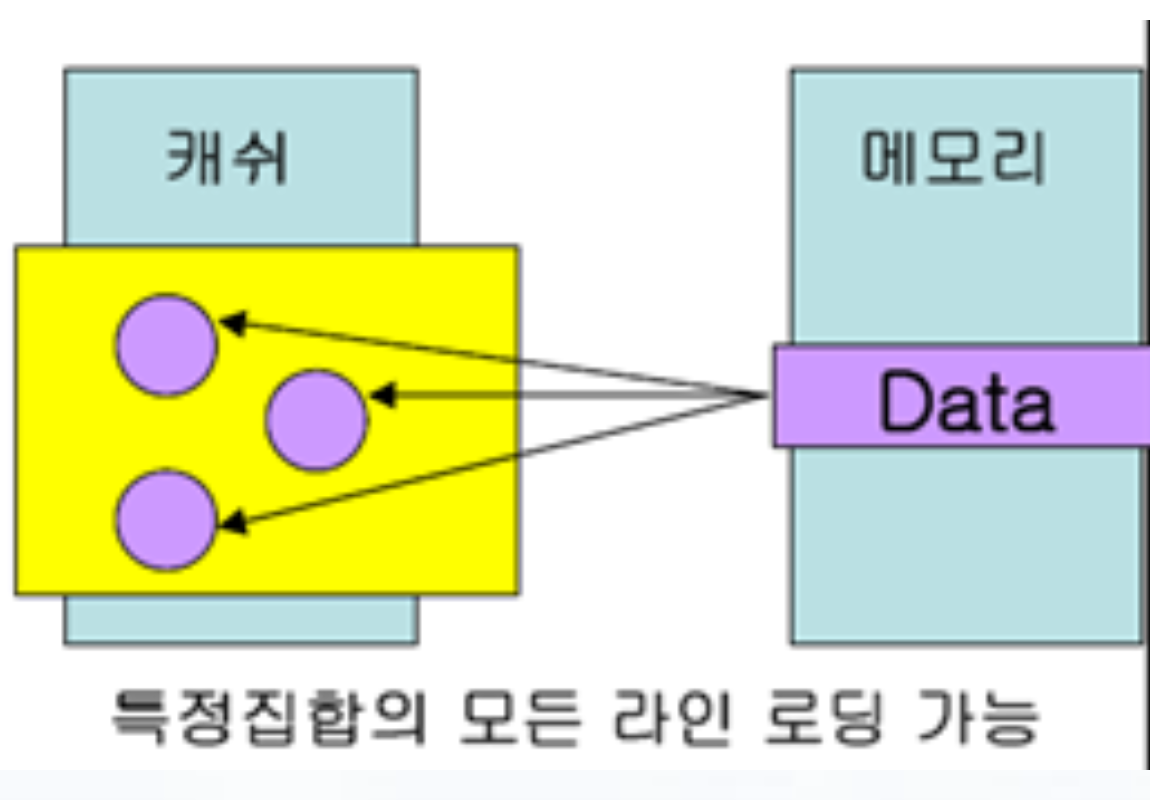
| HW 기법 | 디렉토리 프로토콜 | 캐시의 정보 상태(캐시 블록 공유상태, 노드 등)을 주기억장치 디렉토리에 저장하여 일관성을 보장하는 방법 |
| | Full Map 디렉토리: 디렉토리에 모든 캐시의 포인터와 데이터 저장 |
| | Limited 디렉토리: Full Map 디렉토리의 기억장소 부담 감소 |
| | Chained 디렉토리: 캐시 포인터를 linked list로 연결, 기억장소 부담 감소 |
| | Passive한 방법이며 다중서버 복잡한 시스템에 적합 |
| 스누피 프로토콜 | 멀티 프로세서 내의 모든 캐시 제어기에 캐시 일관성 유지를 위한 정보를 브로드캐스트하는 기법 |
| | 스누피 제어기: 다른 프로세서에 의한 메모리 액세스 감지 후 상태 조절 |
| | 쓰기 갱신(Write Update): Write 발생 시 모든 캐시에 갱신된 정보 전송 |
| | 쓰기 무효(Write Invalidate): Write 발생 시 Invalid 메시지로 브로드캐스팅 |
| | MESI 프로토콜: Modified(수정), Exclusive(배타), Shared(2개 이상의 캐시에 공유), Invalid(무효, 다른 캐시가 수정) 4가지 상태로 데이터 유효성 여부 판단 |
| | Active한 방법, 소규모 시스템, 높은 버스 대역폭 |
| 프로토콜 | 기타 프로토콜 | MEI, MSI, MOESI, MESIF 프로토콜 |
| | O(Owned): 변경 상태의 캐시 블록을 다른 곳에서 읽은 경우 |
| | F(Forwarding): 여러 프로세서가 공유한 캐시 블록 접근 시 |