FDA +011
· 4 min read

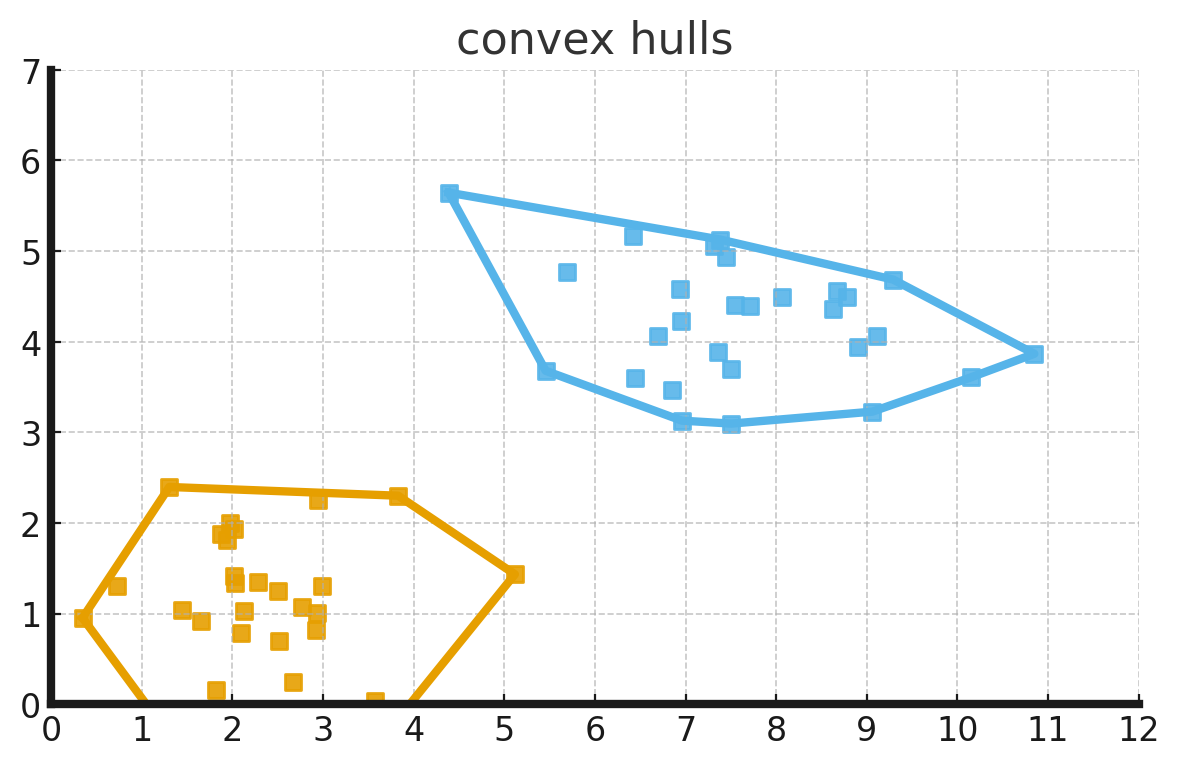
Bias
- Bias quantifies how much on average the predicted values differ from the actual values.
- High bias implies the model is under-performing.
Variance
- Variance quantifies how sensitive the model is to small changes in the training samples.
Ensemble Methods
- The intuition behind ensemble methods is to decrease bias and variance by using multiple machine learning algorithms.
- Any machine learning algorithm can be used in ensemble methods.
- decision trees, neural networks, logistic regressions, etc.
- Base models are as diverse as possible.
- Train each base model to predict as accurately as possible.
Sequential ensemble methods
- Arrange weak learners in a sequence, such that weak learners learn from next learner in the sequence to create better predictive models.
- Each model fits the residual of its predecessor.
Parallel ensemble methods
- to use different variations of the same dataset, of the smae classifier, and aggregate the results.
Bootstraping
- Sampling technique that creates multiple subsets of datasets from the original dataset.
- when inferring results for a population from results found on a collection of smaller random samples of that population.
Bagging
Bootstrap aggregating
- Generates subsets (bags) of traning data by sampling from the original training dataset with replacement.
- To overcome the complexity of models that overfit the training data.
Boosting
- fits multiple models sequentially
- each model in the sequence is fitted giving more weight to the data points that were poorly handled by the previous models in the sequence.
- This process is iterated until the error function does not change, or the maximum limit of the number of estimators is reached.
Random Forest
- Shallow trees have lower variance and higher bias, whereas deep trees have low bias but high variance.
- Shallow trees are chosen for sequential ensemble methods
- Deep trees are chosen for bagging methods (or parallel ensemble methods).
- a bagging method where deep trees are used and fitted on bootstrap samples, and then combined to produce an output with lower variance.
- selects randomly a set of features which are then used to decide the best split at each node of the tree.
- can be applied to both regression and classification tasks.
- can learn binary features, categorical features and numerical features.
- create from the original dataset multiple bootstrap samples.
- at each node in the decision tree, a random set of features is considered to decide the most beneficial split.
- train a decision tree on each bootstrap sample.
- final prediction is computed by averaging the prediction from all decision trees combined.
Advantages of Random Forest
- generally accurate, quick to train
- can handle very large datasets
- can estimate importance of features
- generates an internal unbiased estimate of accuracy, which can use to know when to stop buildling
- can handle missing data
- can handle datasets with imbalanced classes
- can compute proximity between data points
- unsupervised for clustering and outlier detection
but don't handle large numbers of irrelevant attributes as well as some other methods.
Applications of Random Forest
| Industry | Applications | Purpose / Advantages |
|---|---|---|
| Finance | Assessing high credit-risk customers, detecting fraud, and addressing option pricing problems | Preferred over other algorithms due to its ability to minimize time spent on data management and pre-processing tasks |
| Healthcare | Gene expression classification, biomarker discovery, and sequence annotation | Helps doctors estimate drug responses to specific medications |
| E-commerce | Recommendation engines | Used to achieve cross-selling objectives |
AdaBoost
Adaptive Boosting
- simplest boosting algorithm, usaully uses decision trees for modelling
- multiple sequential models are created, each correcting the errors from the previous model.
GBM
Gradient Boosting Machine
- works on both regression and classification problems.
- usually, regression trees are used as base models.
XGBoost
eXtreme Gradient Boosting
- another implementation of gradient boosting algorithm.
- has proven to be a highly effective machine learning algorithm.
- extensively used in machine learning competitions due to its speed and performance.
Combining predictions
Voting
- Hard voting selection process uses predicted class labels for majority rule voting.
- Soft voting uses the predicted probabilities given by each base model, and the class label with the maximum sum of its probabilities is selected.
- where is the number of base models, and is the probability predicted by model for class given input .