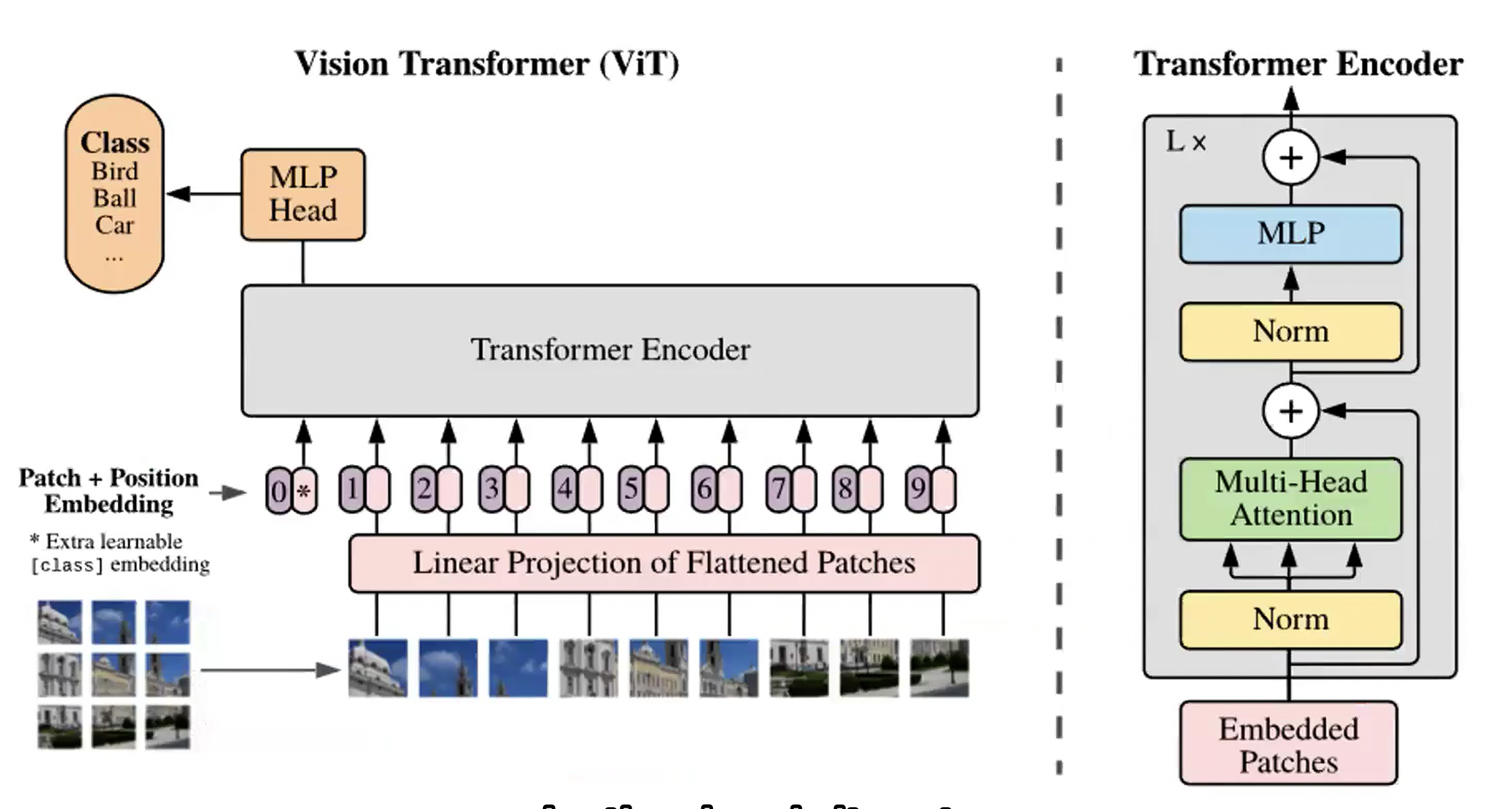
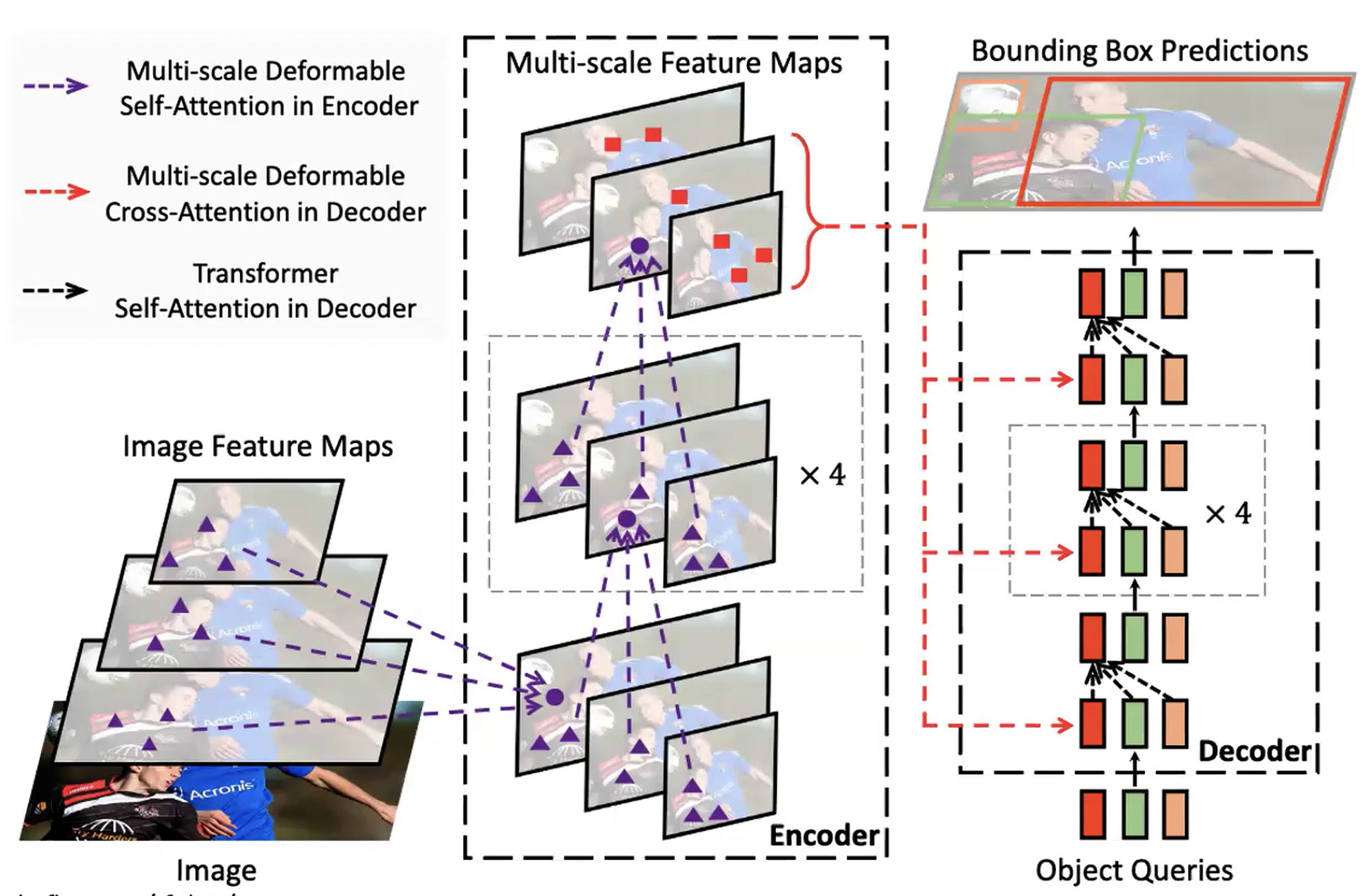
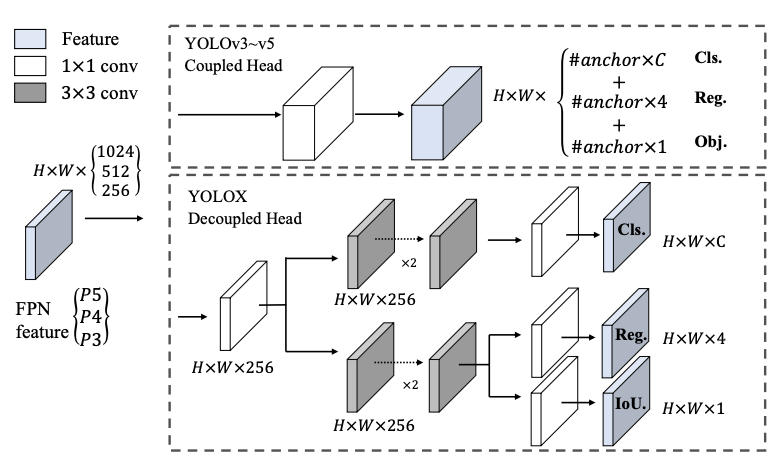
CNN 012
· 6 min read

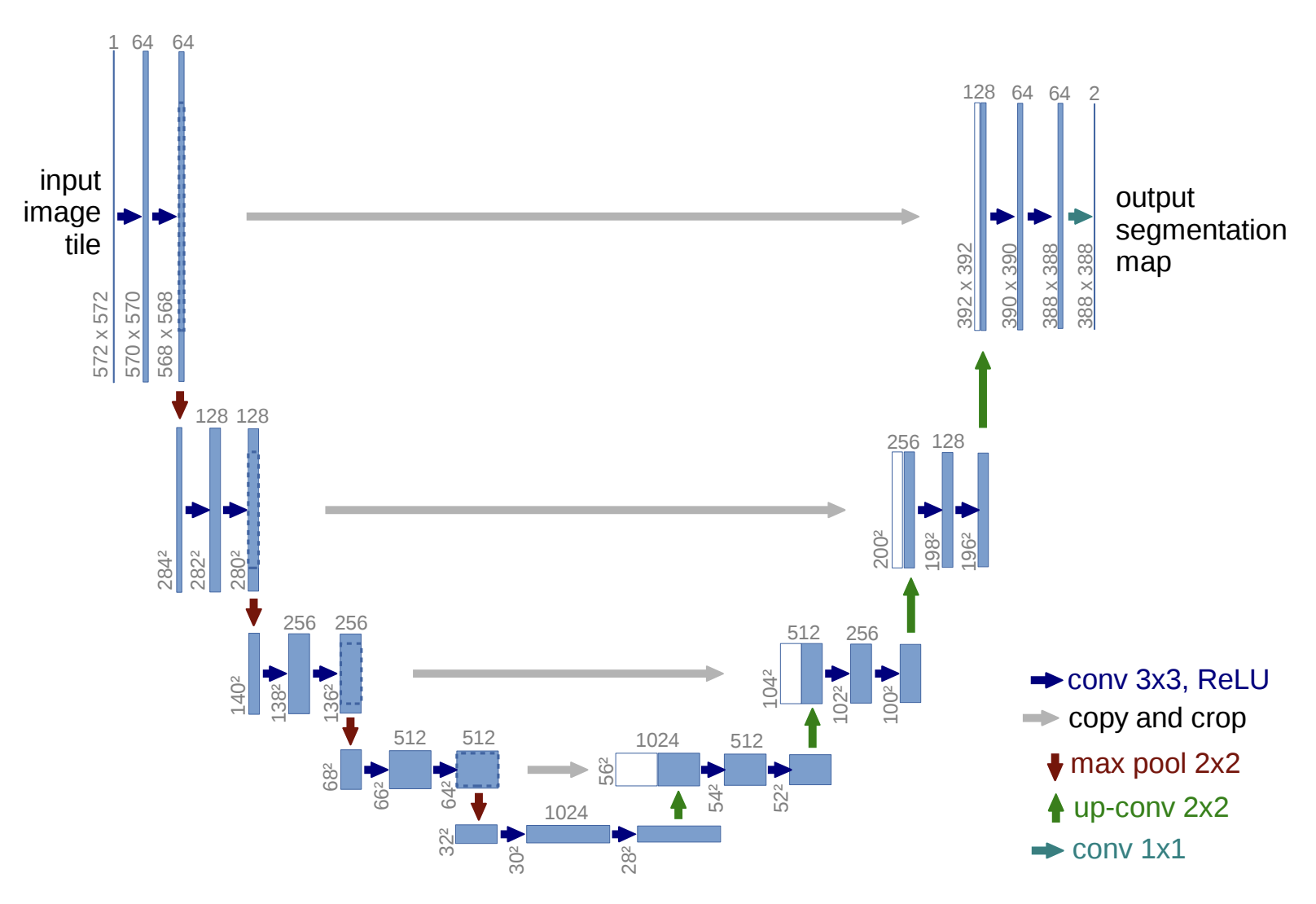
- Three main layers of a CNN
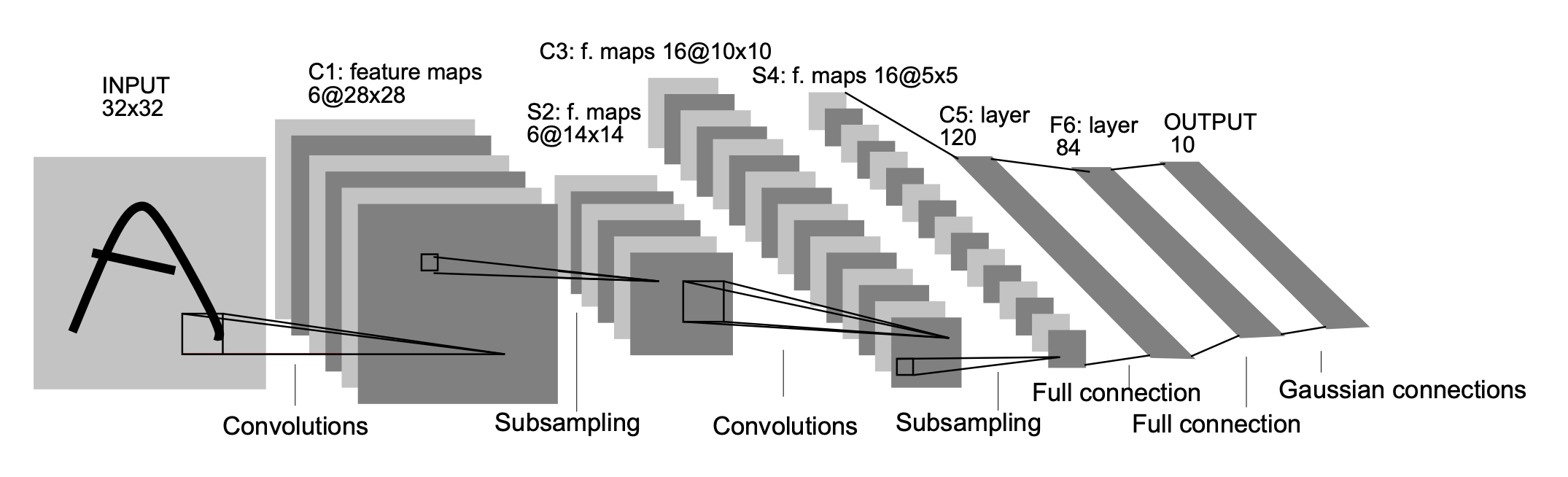
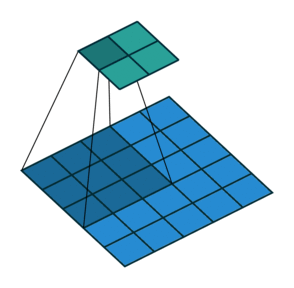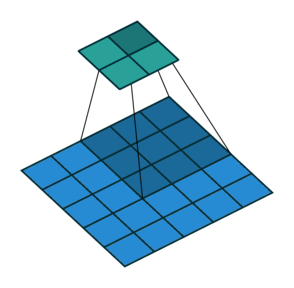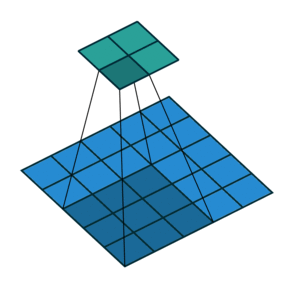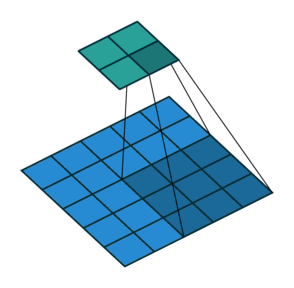
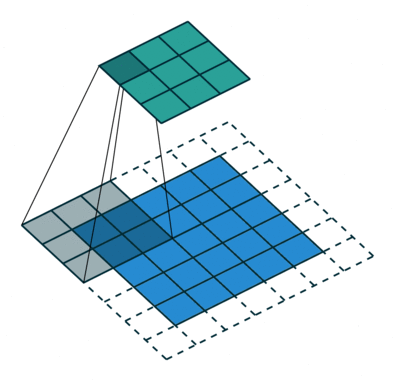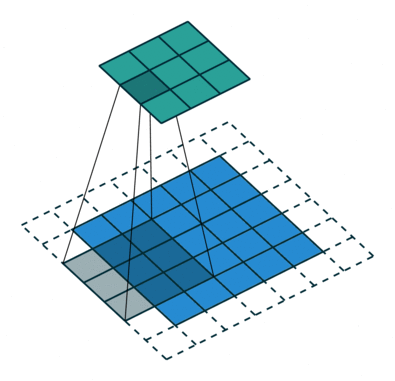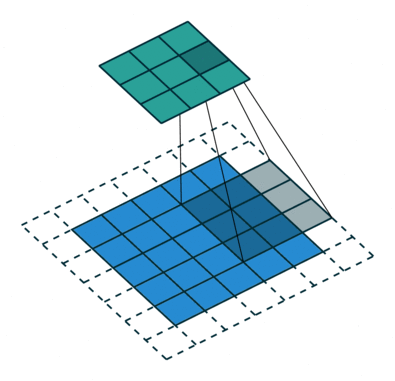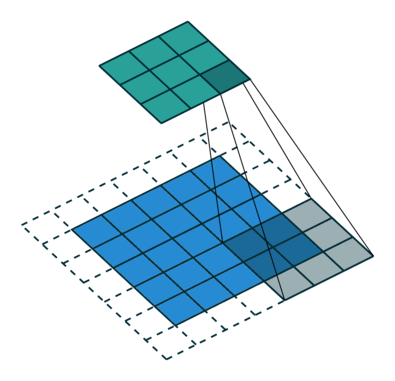
- CONV: Convolution Layer
- POOL: Pooling Layer
- FC: Fully Connected Layer
- CONV extracts features, POOL downsamples feature maps, and FC makes the final prediction.
- Why CNNs use over ANNs for image processing
- Computationally efficient
- Using Filters to capture spatial features
- Sharing weights across the image
- Overfitting
- The model essentially memorizes the training data, leading to poor performance on unseen data
- To prevent overfitting, we can use techniques like:
- Dropout: Randomly dropping out neurons during training to prevent co-adaptation
- Batch Normalization: Normalizing the inputs of each layer to stabilize learning
- L1/L2 Regularization: Adding a penalty to the loss function to discourage large weights
- L1 regularization adds a penalty based on the absolute value of the weights (can be zero, can make model sparse and useful for feature selection.)
- L2 regularization adds a penalty based on the squared value of the weights (not can be zero, reduce model complexity and overfitting.)
- Data Augmentation: Creating new training samples by applying transformations to existing data
- ReLU
- If the input is below zero, ReLU does output
0. - If the input is above zero, it outputs the input value itself.
max(0, x)- ReLU can output any number from
0toinfinity, which allows it to capture a wide range of features in the data. - It fixes gradient vanishing problem by allowing gradients to flow through the network without being squashed to zero, which can happen with activation functions like sigmoid or tanh.
- If the input is below zero, ReLU does output
- Sigmoid: Binary Classification
- Softmax: Multi-class Classification
- Backpropagation: sends the error backward through the network and calculates gradients, so the model knows how to update its weights and biases.
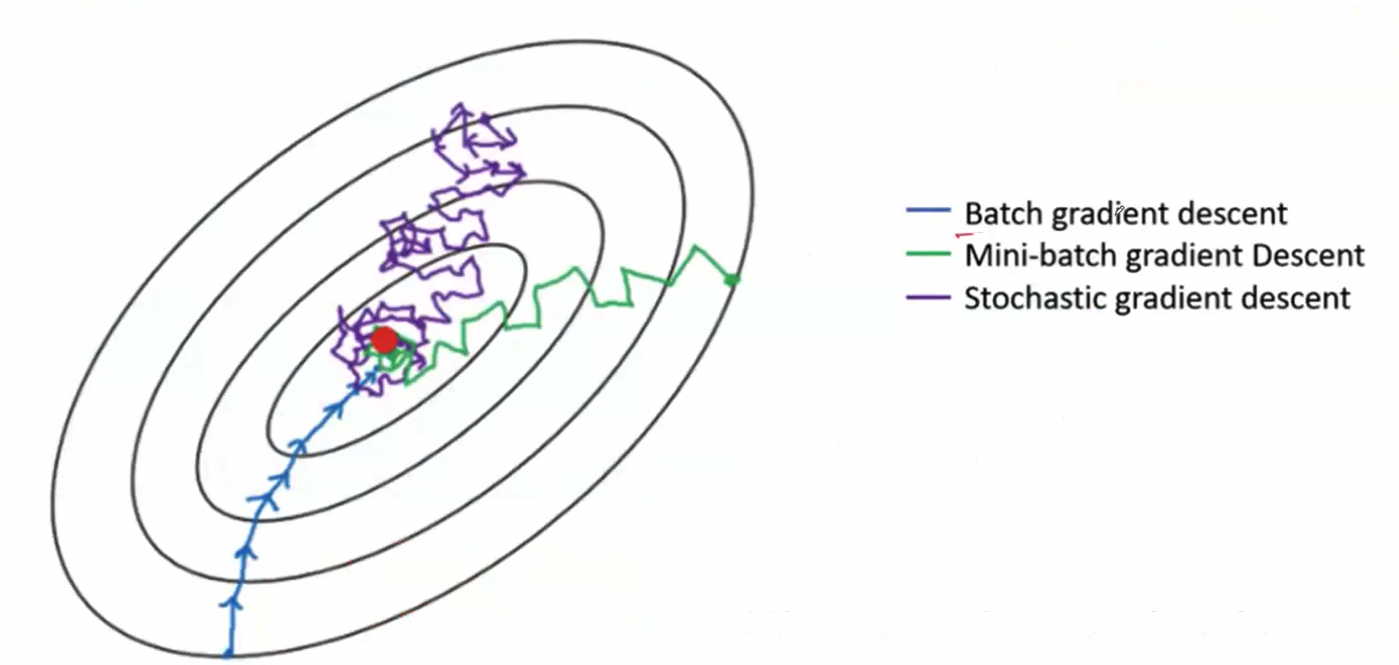
- Gradient Descent
- It uses Backpropagation to calculate the exact slope (the gradient) of the error (loss).
- Then it takes a step in the opposite direction of the gradient to minimize the error.
- It repeats this interative process until it reaches a local minimum.
- Vanishing Gradient Problem
- The gradient becomes too small, so earlier layers learn very slowly or almost stop learning.
- ReLU helps mitigate this problem by allowing gradients to flow through the network without being squashed to zero.
- Learning Rate
- It's a hyperparameter that controls how big of a step the model takes down the slope.
- If is too small, the model will take tiny steps and may take a long time to converge.
- If is too large, the model may overshoot the minimum and diverge.
- Precision:
- Of all the patients the model predicted as having the disease, how many actually have the disease?
- Recall:
- Of all the patients who actually have the disease, how many did the model successfully catch?
- Recall is more important in medical diagnosis because we want to minimize false negatives (missing a disease).
- Sliding Window
- Computationally expensive because it requires multiple passes over the image with different window sizes and strides.
- Multiple scales are needed to detect objects of varying sizes, which further increases the computational cost.
- Stride: controls the step size of the sliding filter. Larger stride means smaller output.
- Edge
- The points or pixels in an image where brightness or intensities change sharply.
- Sobel filter
- Prewitt filter
- Canny edge detector
- Padding: adds zeros around the image so the CONV does not shrink the feature map too much.
- Keep the output dimension the same as the input dimension, we can use padding.
- Image Classification: Assigning a label to an entire image (e.g., cat, dog, car).
- Object Detection: Identifying and localizing multiple objects within an image (e.g., bounding boxes)
- Instance Segmentation: Identifying and segmenting each object instance in an image (e.g., pixel-level masks)
- Momentum: uses an exponentially weighted average of past gradients to smooth updates and accelerate convergence.
- RMSProp: uses an exponentially weighted average of squared gradients to adapt the learning rate for each parameter.
- Adam: combines Momentum and RMSProp by using both the first moment, average gradient, and the second moment, average squared gradient.
- Hyperparameters: learning rate, batch size, number of epochs, optimizer type, dropout rate, etc.
- Supervised Learning: The model learns from labeled data, classification, regression.
- Unsupervised Learning: The model learns from unlabeled data, clustering.
- Loss/Cost function: an estimate of how far the model's predictions are from the actual target/answer.
- AI is a broad concept of machines performing human-like tasks.
- ML is a subset of AI that learns from data
- DL is a subset of ML that uses deep neural networks with many layers.
- ML's major problem
- insufficient data
- non-representative training data
- poor-quality data
- irrelevant features
- overfitting
- underfitting
- When we use ML?
- a large amount of data for finding patterns and making predictions
- too many rules or too much complexity for humans to handle
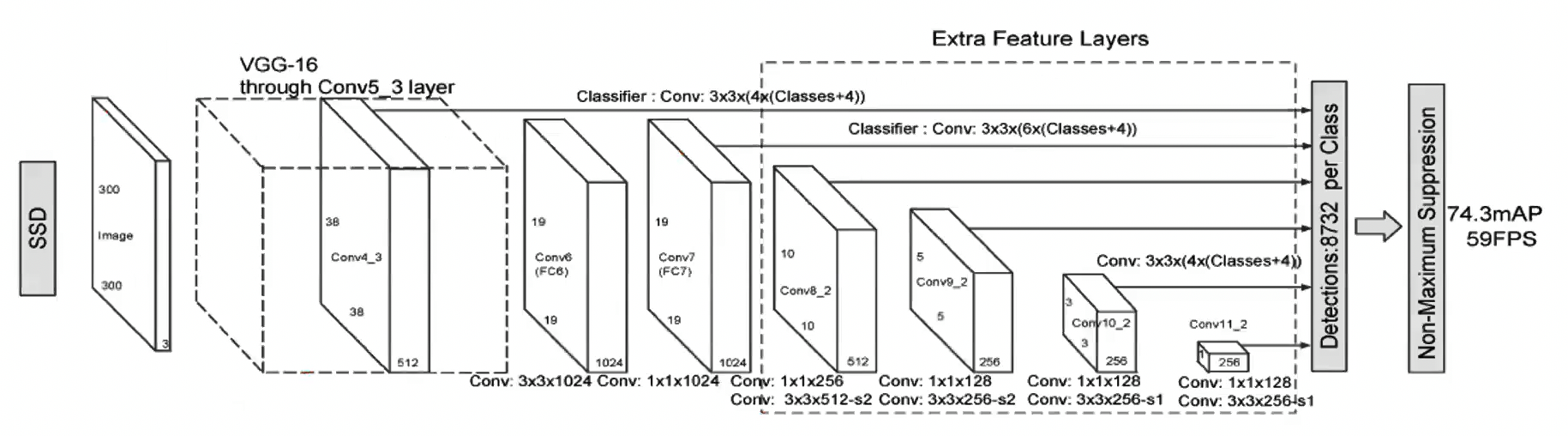
- Faster R-CNN: Propose regions first, then classify them
- RPN: Region Proposal Network, which generates candidate object proposals
- YOLO: Predict boxes and class probabilities directly from the image in one pass
- Anchor boxes: predefined bounding boxes of different sizes and aspect ratios used to predict the location of objects in YOLO.
- NMS: Non-Maximum Suppression, selects the best bounding box among overlapping boxes based on confidence scores.
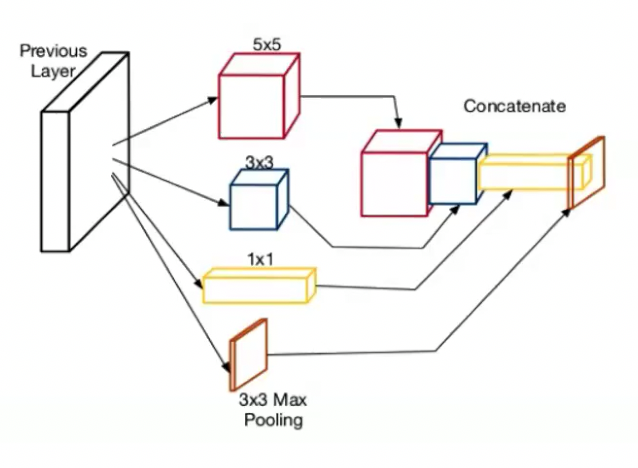
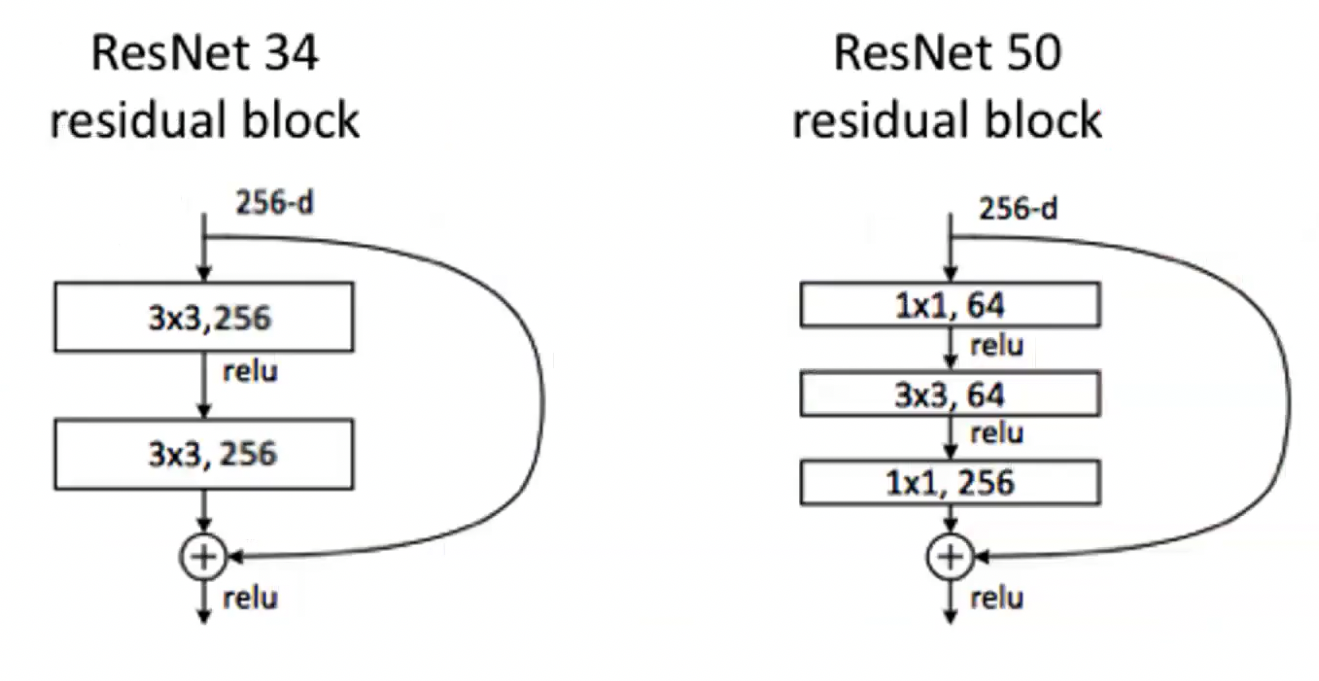
- 1×1 convolution mixes channel information and can reduce the number of channels, so later convolutions become cheaper.
- Inception module: learns small, medium, and large visual features at the same time.
- Transfer Learning Strategies:
- First, if the new dataset is small and similar to the original dataset, we can use the pre-trained model directly.
- Second, if the dataset is similar but has different classes, we freeze the convolutional layers and train only the fully connected classification layer.
- Third, if the dataset is small but not very similar, we freeze the early convolutional layers and fine-tune the later convolutional layers plus the FC layer.
- Finally, if the dataset is large and different, we can fine-tune the whole network.
- IoU: Intersection over Union, a metric used to evaluate the accuracy of object detection models by comparing the predicted bounding box with the ground truth bounding box.