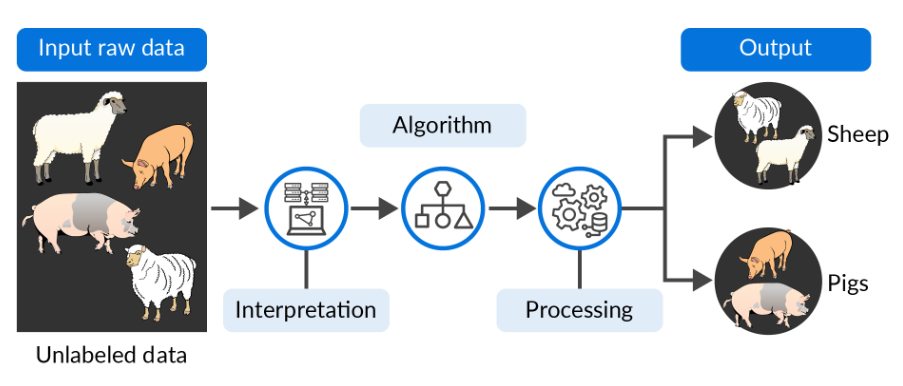
Research methodology
· One min read

Quantitative and Qualitative Methods
| Category | Sub Category | Quantitative | Qualitative |
|---|---|---|---|
| Requirement | Question | Hypothesis | Interest |
| Method | Control and randomization | Curiosity and reflexivity | |
| Data collection | Response | Viewpoint | |
| Outcome | Dependent variable | Accounts | |
| Ideal | Data | Numerical | Textual |
| Sample size | Large (power) | Small (saturation) | |
| Context | Eliminated | Highlighted | |
| Analysis | Rejection on null | Synthesis |
Types of Research Methodology
- Historical: Qualitative
- Comparative: Qualitative
- Descriptive: Qualitative
- Correlation: Quantitative
- Experimental: Quantitative
- Evaluation: Qualitative
- Action: Qualitative
- Ethnographic: Various (not quantitative)
- Ethnogenic: Various (not quantitative)
- Feminist/Identity Politics: Various (not quantitative)
- Cultural: Various (not quantitative)
Common data collection methods
Qualitative data collection methods
- Observations: recording what you have seen, heard, or encountered in detailed field notes
- Interviews: asking people questions in one-on-one conversations
- Focus groups: asking questions and generating discussion among a group of people
- Surveys: distributing questionnaires with open-ended questions
- Secondary research: collecting existing data in the form of texts, images, audio or video recordings, etc.
Quantitative data collection methods
- Experiments
- Computer Simulation and Agent-Based Models
- Controlled observations
- Surveys: paper, kiosk, mobile, questionnaires
- Longitudinal studies
- Polls and Telephone interviews
- Face-to-face interviews