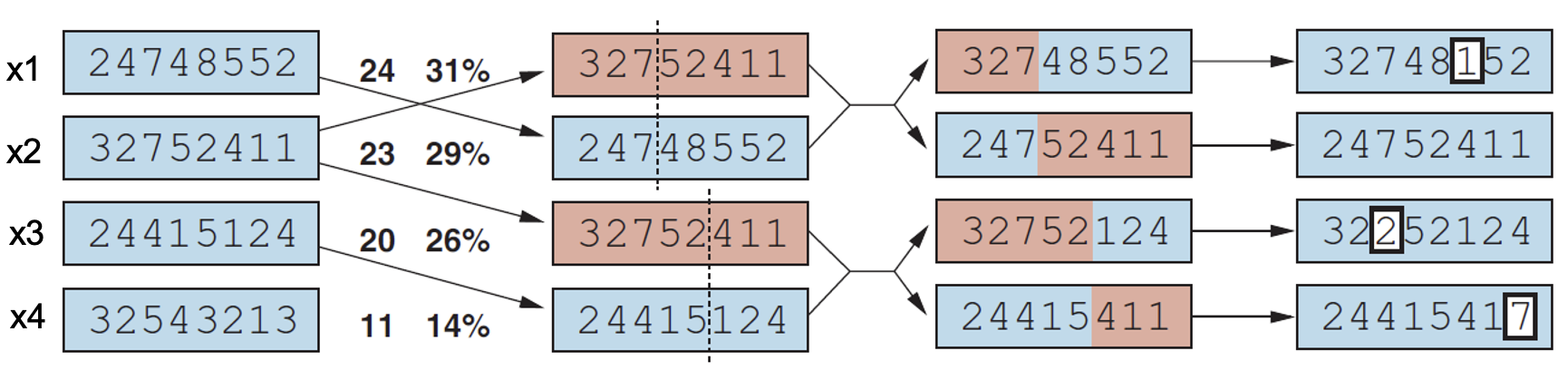
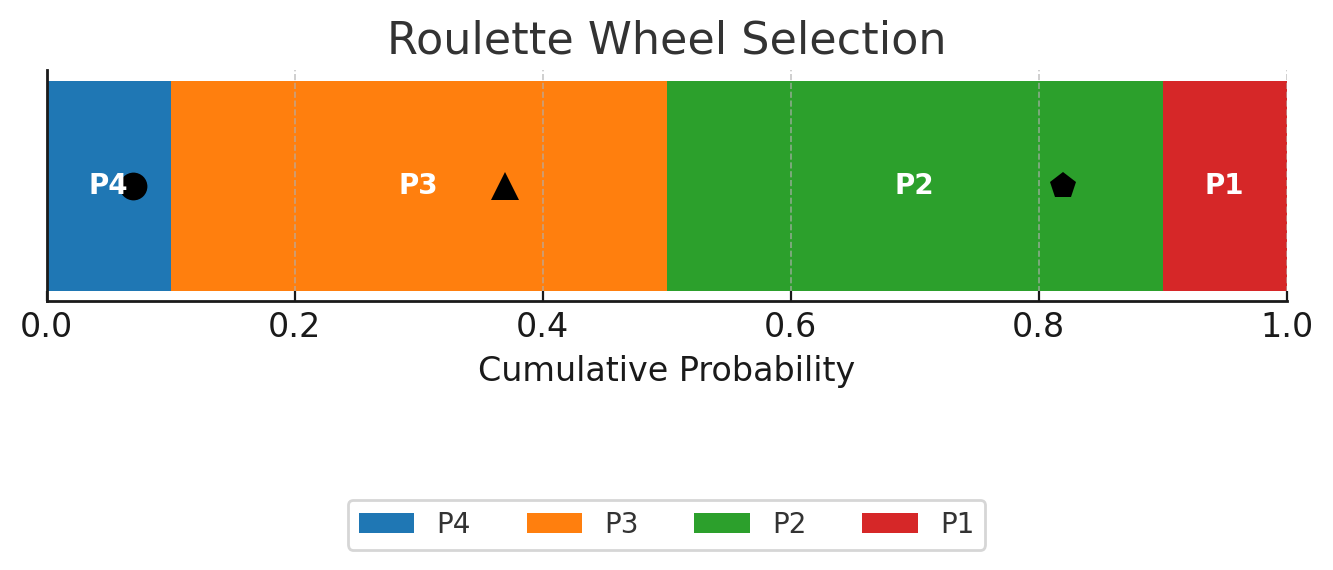
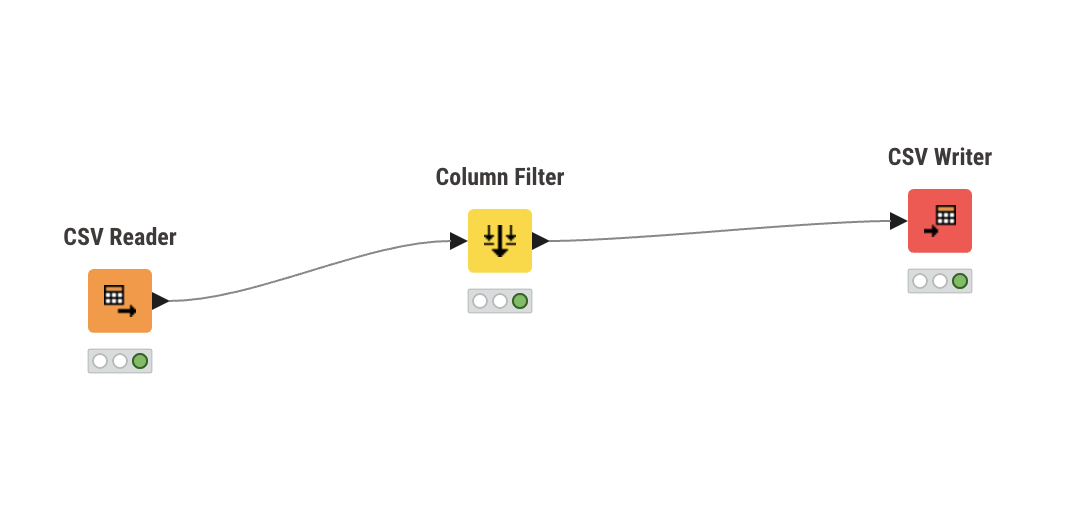
FSD +004
· One min read

match
match term:
case pattern-1:
action-1
case pattern-2:
action-2
case pattern-3:
action-3
# the underscore _ case executes the default code
case _:
action-default
Repetition Statements
- The count-controlled repetition: a fixed number of times.
- The sentinel-controlled repetition: a designated value that ends the loop.
- The infinite repetition: continues until externally stopped.
The For Loop
for <value> in <range of values>:
<code>
sum = 0;
# [1, 2, ..., 19]
# adds values from 1 to 19 to sum
for e in range(1, 20):
sum += e
print(f"The sum is: {sum}")
Loop-And-A-Half
n = 5
sum = 0
while n < 10:
sum += n
if sum > 100:
break