OpenVLA Review
· 3 min read

OpenVLA
- OpenVLA is a 7B open-source VLA model built on Llama2 + DINOv2 + SigLIP, trained on 970k demos, achieving stronger generalization and robustness than closed RT-2-X (55B) and outperforming Diffusion Policy.
- It introduces efficient adaptation via LoRA (1.4% params, 8× compute reduction) and 4-bit quantization (half memory, same accuracy), enabling fine-tuning and inference on consumer GPUs.
- Limitations remain (single-image input,
<90%reliability, limited throughput), but OpenVLA provides the first open, scalable framework for generalist robot policies.
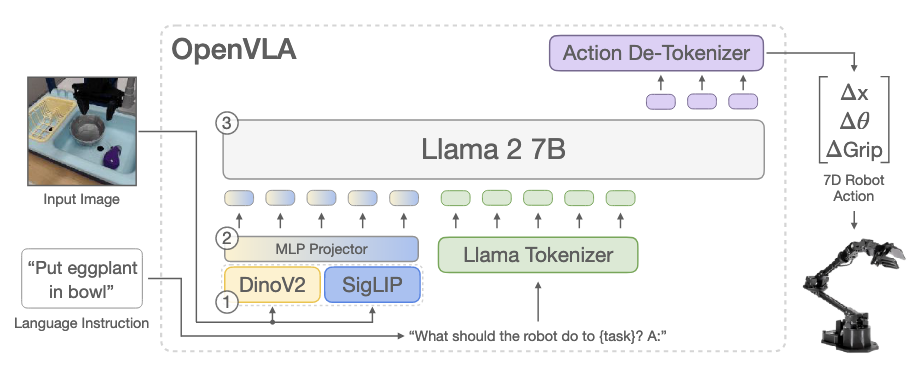
Motivation
- Training robot policies from scratch struggles with robustness and generalization.
- Fine-tuning vision-language-action (VLA) models offers reusable, generalizable visuomotor policies.
- Barriers: prior VLAs are closed-source, lack best practices for adaptation, and need server-class hardware.
Model & Training
- OpenVLA: 7B parameters, open-source.
- Built on Llama 2 with fused DINOv2 + SigLIP vision encoders.
- Trained on 970k robot demonstrations from Open-X Embodiment dataset.
- Represents robot actions as tokens (discretized into 256 bins, replacing unused Llama tokens).
- Standard next-token prediction objective.
Architecture & Approach
- End-to-end fine-tuning of VLM to generate robot actions as tokens.
- Differs from modular methods (e.g., Octo) that stitch separate encoders/decoders.
- Vision features are obtained by encoding the same input image with both SigLIP and DINOv2, then channel-wise concatenated and passed through an MLP projector. This preserves SigLIP’s semantic alignment with language and DINOv2's spatial reasoning, giving the VLM richer multimodal context for manipulation tasks.
- Uses Prismatic VLM backbone with multi-resolution features (spatial reasoning + semantics).
Performance
- Outperforms closed RT-2-X (55B) by +16.5% task success with 7× fewer parameters.
- Beats Diffusion Policy (from-scratch imitation learning) by +20.4% on multi-task language-grounded settings.
- Demonstrates robust behaviors (distractor resistance, error recovery).
Efficiency
- Introduces parameter-efficient fine-tuning:
- LoRA updates only 1.4% of parameters yet matches full fine-tuning.
- Can fine-tune on a single A100 GPU in ~10–15 hours (8× compute reduction).
- Quantization:
- 4-bit inference matches bfloat16 accuracy while halving memory footprint.
- Runs at 3Hz on consumer GPUs (e.g., A5000, 16GB).
Evaluations
- Tested across 29 tasks and multiple robots (WidowX, Google robot, Franka).
- Strong generalization on:
- Visual (unseen backgrounds/distractors).
- Motion (new object positions/orientations).
- Physical (new object shapes/sizes).
- Semantic (unseen tasks, instructions).
- First generalist open-source VLA achieving ≥50% success rate across all tested tasks.
Design Insights
- Fine-tuning the vision encoder (vs. freezing) crucial for robotic control.
- Higher image resolution (384px vs. 224px) adds 3× compute without performance gains.
- Training required 27 epochs, far more than typical VLM runs, to surpass 95% action token accuracy.
Limitations & Future Work
- Supports only single-image observations (no proprioception, no history).
- Inference throughput (~6Hz on RTX 4090) insufficient for high-frequency control (e.g., ALOHA at 50Hz).
- Success rates remain below 90% in challenging tasks.
- Open questions:
- Impact of base VLM size on performance.
- Benefits of co-training with Internet-scale data.
- Best visual features for VLAs.
Contributions
- First open-source generalist VLA with strong performance.
- Scalable end-to-end training pipeline (action-as-token).
- Demonstrates LoRA + quantization for consumer-grade GPU adaptation.
- Provides code, checkpoints, and data curation recipes to support future research.
Ref
- Kim, M. J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E. P., Sanketi, P. R., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., & Finn, C. (2025). OpenVLA: An Open-Source Vision-Language-Action Model Proceedings of The 8th Conference on Robot Learning, Proceedings of Machine Learning Research.
https://proceedings.mlr.press/v270/kim25c.html