CNN 007
· 약 6분

Transfer Learning
- Knowledge acquired while solving one task, can be used to solve related tasks
- Similar to the way humans apply knowledge acquired from on task to solve a new but similar, related task.
Transfer Learning Benefits
- Less training data required: Model trained using a large (similar) dataset can be used as a starting point for training on a smaller dataset.
- Faster training: Traninig can converage faster, du the use to existing knowledge (weights) to start with rather than from scratch.
- Better model generalization: Model is trained to identify features which can be applied to new contexts.
VGG-16
| Approach | Description | Use Case | When to Use |
|---|---|---|---|
| Use Pre-trained Model | Use ImageNet pre-trained model without any additional training | Dogs & cats classification | When dataset distribution is similar to ImageNet with few samples |
| Train FC Layers Only | Use CONV layers for feature extraction, train FC layers only | Different class classification on similar domain | When dataset is similar to ImageNet but different classes with limited samples |
| Train Last CONV + FC Layers | Train last CONV layers (specialized features) and FC layers | Significantly different data distribution domain | When dataset differs greatly from ImageNet, different classes, and limited samples |
| Train All CONV + FC Layers | Train all CONV layers and FC layers (with modifications) | Complex task with different domain | When dataset differs greatly from ImageNet, different classes, dataset is large, and task is complex |
AlexNet
- Input: 224x224x3 image
- Activiations: ReLU after each CONV and FC layer
- Optimizer: SGD with Momentum
- Regularization: Dropout in FC1 and FC2
- Total Trainable Parameters: ~60 million
- Traninig settings: Nvidia GTX 580 3BG GPUs for 6 days
GoogleNet
- Accurary: top-5 test erorr rate of 6.7%
- Close to human level performance
- 22 layer deep CNN
- Optimizer: RMSProp
- Total Trainable Parameters: ~4 million (Significantly reduced)
- A novel inception module was introduced
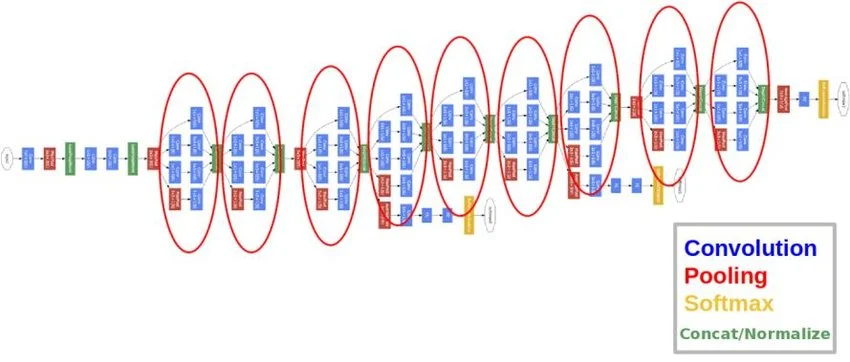
Inecption Module
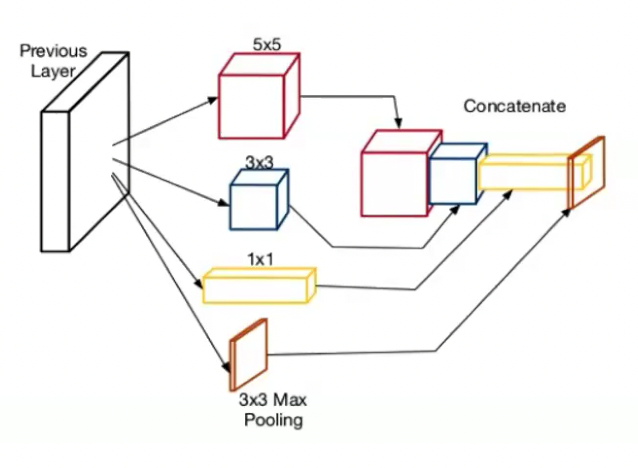
- Use filters with different size together
- Use different types of layers (CONV, POOL etc.) together
- It leads to better performance and efficiency but complicated architecture.
1X1 Convolution
Input image (), 1x1 kernel, and output can be declared as:
For channel reduction with a 1x1 convolution, each spatial location is a vector:
One 1x1 layer with 128 filters is a matrix:
At each location, output channels are computed by matrix multiplication:
So the shape changes as:
If we flatten all spatial positions ():
Inception V2 and V3
- V1 (GoogleNet): Replace one 5x5 conv with two stacked 3x3 conv layers.
- Number of parameters: vs. (about 28% reduction)
- V2: Factorize an conv into and convs.
- For : vs. (about 33% reduction)
- V3: Use more aggressive factorization and branch design (e.g., and ), plus efficient grid-size reduction.
- Improves the accuracy-efficiency tradeoff while keeping computation manageable
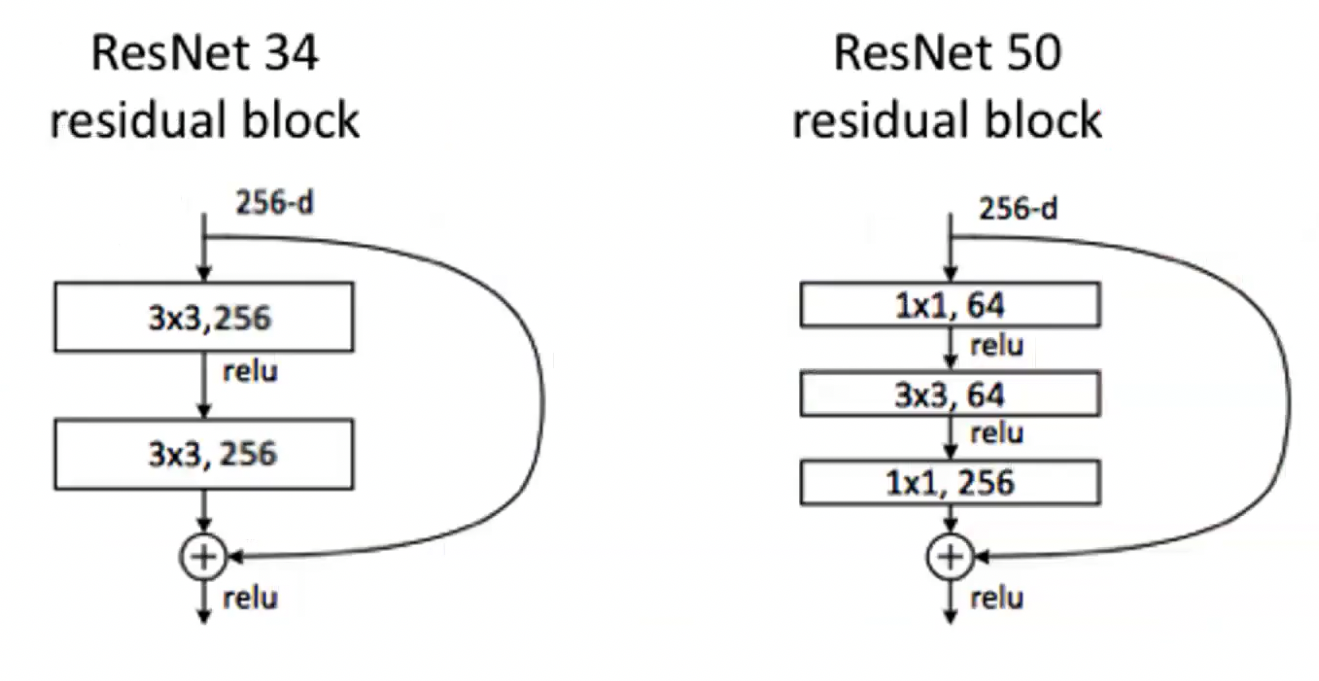
ResNet
Deep Residual Networks, skip connections, and identity mappings
- Enabled the development of the much deeper networks
- ResNet is composed of residual blocks were introduced to address the vanishing gradient problem in deep networks.
- Degradation problem: adding more layers eventually have negative effect on the final performance