CNN 004
· 약 6분

Logistic Regression as Neural Network
- if
- if , then (low loss)
- if , then (high loss)
- if
- if , then (low loss)
- if , then (high loss)
Gradient Descent
- it is an iterative approach for error correction in a machene learning model
- Find and that will minimize (requires Loss/Cost function)
- Initialize and
- Perform Forward pass operation/calculations
- Compute Loss/Cost function
- Compute change in and (Take the partial derivative of the cost function with respect to Weights and bias and )
- Update and ( and )
- Repeat from Step 2 with new values of and for 'n' number of iterations.
- is the learning rate (hyperparameter) that controls how much we are adjusting the weights and bias of our model with respect to the loss gradient. It is a small positive value (e.g., 0.01, 0.001) that determines the step size at each iteration while moving toward a minimum of the loss function.
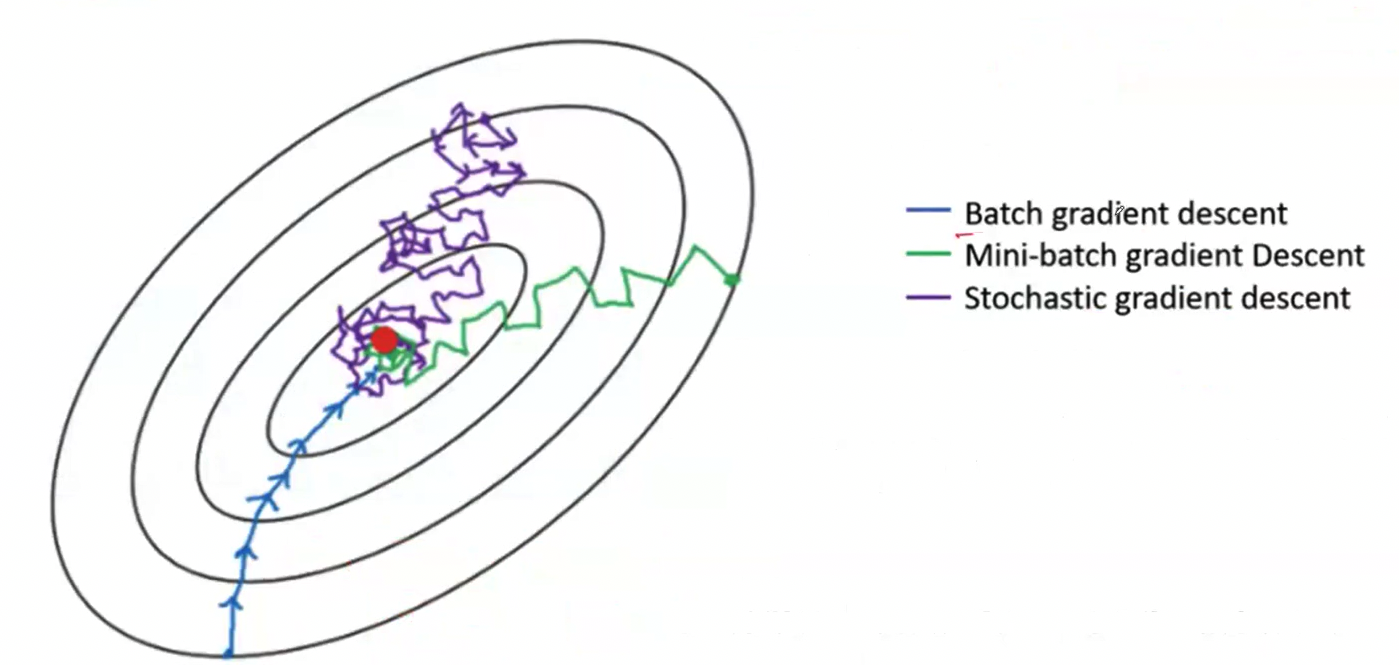
Gradient Descent Types
- Batch Gradient Descent (BGD)
- Stochastic Gradient Descent (SGD)
- Mini-batch Gradient Descent (MBGD)
Batch Gradient Descent (BGD)
- Process each input sample and find the cost
- Find the average cost oveer all input samples
- Update and and repeat the steps for "n" epochs(iterations)
- Disadvantages:
- It uses the complete dataset to calculate the gradients at every steps
- Slow when training data is large
- Difficult to find the learning rate
- Difficult to ascertain the number of epochs(iterations)
Stochastic Gradient Descent (SGD)
Due to the random nature, the algorithm is much less regular than BGD.
- Process a random input sample and find the cost.
- Update and , and repeat the steps for "n" iterations on the training samples.
- Advantages:
- Computes gradient based on single input sample, which is memory efficient.
- Much faster compared to BGD.
- Possible to train on large datasets.
- Randomness is helpful to escape local minima.
- Disadvantages:
- Might not reach the optimal value, but very close to it.
- Simulated annealing: Reduce the learning rate gradually
- Create a Learning Schedule to determine the learning rate at each iteration.
- Might not reach the optimal value, but very close to it.
Mini-batch Gradient Descent (MBGD)
- Divide the tranining set into mini-batches of size (e.g., 64, 128, 256).
- Process all the samples in a mini-batch and find the average cost
- Update and , and repeat the steps for "n" iterations/epoches on the traning samples.
- Advantages:
- Computes gradient based on small sets of input smaple
- Much faster compared to BGD.
- Possible to train on large dataset.
- Performance boost on matrix operations using GPUs.
- Might not reach the optional value but, very close to it and possibly better than SGD.
- Disadvantages:
- It may be harder to escape the local minima compared to SGD.
Exponentially Weighted Averages
- One of the popular algorithm for smoothing sequential data (time series data), aka. moving average.
- Weight the number of observations and using their average
is approximate average over time steps.
- For , is average over the last 10 time steps.
- For , is average over the last 50 time steps.
- For , is average over the last 2 time steps.
Optimizers
SGD with Moementum
At iteration :
- Calculate and on the current mini-batch (Hyper parameters: and )
- Update the velocity:
- Update parameters:
RMSProp
- Root Mean Square Propagation.
- Unpublished adaptive learning method by Geoffrey Hinton.
- Reduces oscillation but in a different way than Momentum.
- Divides the learning rate by an exponentially decaying average of squared gradients.
- Calculate and on the current mini-batch
- Update parameters:
- is a small number to prevent division by zero (e.g., )
Adam
- Adaptive Moment Estimation
- Combination of RMSProp and Momentum
- Work well for a wide range of non-convex optimization problems in machine learning.
- Calculate and on the current mini-batch
- Update parameters:
- is a small number to prevent division by zero (e.g., )
- Hyper parameter guide:
- : Momentum term
- : Moving weighted average
- : To prevent division by zero
- ensmallen.org
Learning Rate Decay
- Speed-up the learning algorighm by slowing decreasing the learning rate as the number of epochs increases.
Activation Functions
- Getting the output of a layer in a neural network and applying a non-linear function to it.
- Sigmoid:
- Tanh:
- Used for binary classification in the output layer.
- ReLU:
- Rectified Linear Unit
- Avoids and rectifies vanishing gradient problem
- Best used in hidden layers
- Computationally less expensive than sigmoid and tanh
- Softmax:
- Turns numbers in probabilities that sum to 1.
- Used for multi-class classification in the output layer.