FDA +010
· 약 4분

SVM
a supervised learning framework for finding a boundary between data points belonging to different classes.
Convex Hull
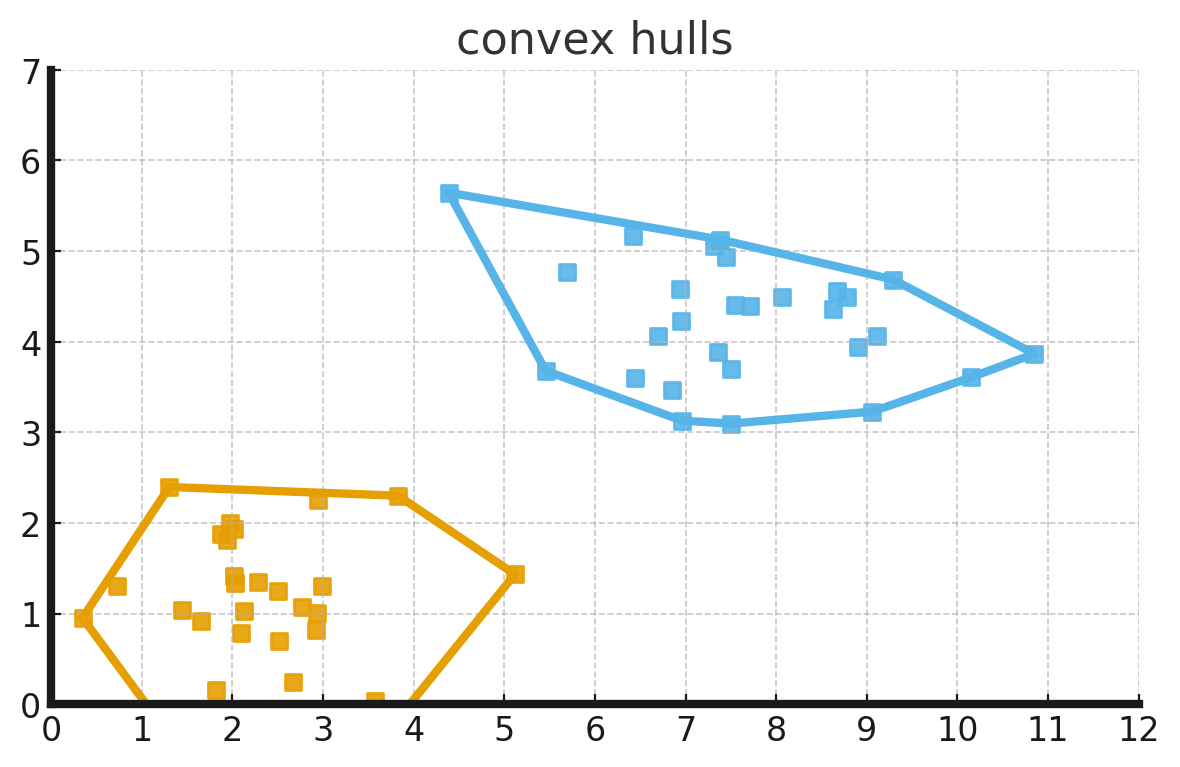
- the lines surrounding the outermost points of each class.
- since the classes are linearly separable, convex hulls do not intersect.
Margins
- the distance between data points of different classes seprarated by a hyperplane.
- multiple possible hyperplanes can separate the classes, but the optimal hyperplane maximizes the margin.
- Maximum Margin Hyperplane
- a separation line/plane orthogonal to the shortest line connecting the convex hull.
- the line that is farthest apart from each convex hull.
- it separates the data points with the widest margin.
Kernels
- kernel is used to represent kernel functions
- which are used to convert low-dimensional space to high-dimensional space
- by applying a function on low-dimensional data points to come up with higher dimensions
- which can be used to linearly separate the data points of classes using a hyperplane.
- the function of a kernel is to take data as input and transform it into the required form.
- different algorithms use different types of kernel functions.
- linear, non-linear, polynomial, radial basis function (RBF), and sigmoid.
Kernel trick
- Basic idea of SVM and Kernel trick is to find the plane which can separate, classify or split the data with maximum margin as possible.
- The distance from a point to a line is given by the formula:
- The distance between , is then: .
- The total distance between and is .
- .
- to maximiza the margin, we need to minimize
- this can be solved through Lagrangian formula or Lagrangian multipliers.
- Setting the gradient of
- The dual form of the optimization problem is:
- Capital letters such as A, X, Y denote matrices;
- Greek letters such as , denote functions;
- lower-case bold letters such as , denote vectors;
- script letters such as , , , denote sets or spaces;
- denotes the norm of vector;
- denotes the Frobenius norm of matrix, and is given by ;
Linear Kernel
Gaussian Kernel / RBF Kernel
Polynomial Kernel
Sequential Minimal Optimization (SMO)
- an algorithm for solving the quadratic programming (QP) problem that arises during the training of support vector machines (SVMs).
Advantages
- Overfitting is unlikely
- SVM uses the maximum margin hyperplane, which is relatively stable.
- the maximum margin hyperplane is only sensitive to the changes in the support vectors.
- the variance in the data may have a relatively low effect on the performance
- Computational complexity
- since every time we need to classify a new sample we need to examine that sample with all the support vectors.
- Using the kernel trick can help to alleviate this by calculating the dot product before doing the nonlinear mapping.
Disadvantages
- not perform very well when the data set has more noise
- where the number of features for each data point exceeds the number of training data samples, the SVM will underperform.
Applications
- Image classification
- Handwriting recognition
- Bioinformatics
- Text classification
- Top 10 SVM Applications